Today we announced our Series A Financing to enable us to expand our cloud service (sign up for early preview!)
Introduction
For the last two years we have been working towards The Intelligent Data API: a way to turn data streams into data products.
Today, Jan 26th, 2021 the world is very different from what it was 10+ years ago, when the majority of data streaming technologies were invented. A decade ago, the bottleneck was disk- ‘ye olde spinning hard drives. The slowness of spinning disks dominated how storage systems were built, because a single misstep would cause your users to experience massive delays. Today’s hardware is like the new Avengers comics, every part is so vastly improved it is hardly recognizable - with modern disks being the new Captain Marvel, 1000x faster.
Over this same decade, we saw the rising need for enterprises to react in real time to the ever increasing data volume, velocity and variety. It was us, consumers, using a phone application anywhere in the world, and being able to hail a cab without speaking the foreign language. Or us, consumers, purchasing a movie on a transatlantic flight and expecting that our credit card would detect a fraudulent transaction due to a double charge, even if it happened mid air at 560 miles per hour all while crossing country boundaries. These expectations have, in a transitive sense, created a renaissance in the real-time infrastructure that powers these businesses. Whether you are combining taxi-driver demand, customer presence with surge pricing or merging 25 different data sources to detect a fraudulent transaction, customers expect you to react to events now in real time.
However, once you decide to move your infrastructure towards an event-driven paradigm, you will soon find yourself drowning in complexity on how to actually operationalize open source components at scale. That’s why we created the Intelligent Data API, a developer centric environment for transforming realtime streams into products, with new primitives for unifying historical and real time data as well as modern day store-procedures for streaming.
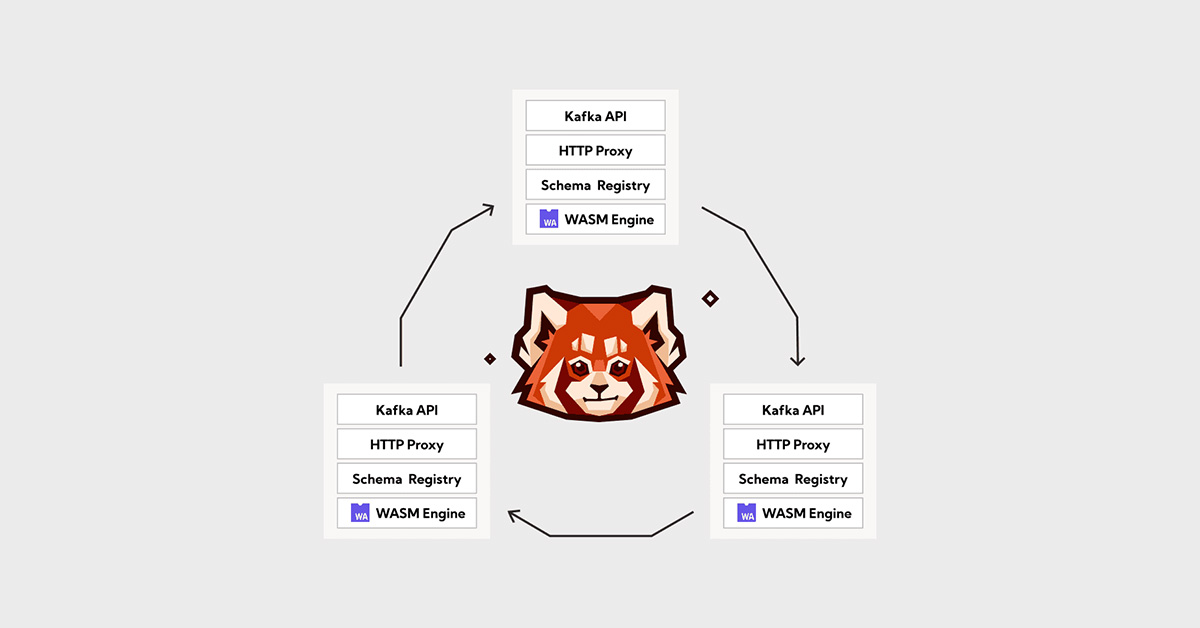
The Intelligent Data API has 3 parts
-
Compatibility with the largest data streaming ecosystem (Apache Kafka® API)
-
Unification of historical and real time data (Shadow Indexing)
-
Stateful stored-procedures for streaming data (WASM)

Part 1: Compatibility with the largest data streaming ecosystem: The Kafka API

Let’s be clear, engineers absolutely love the Kafka API. What they love is the fact that they can take TensorFlow, Spark Streaming, and ElasticSearch and have a sophisticated fraud detection pipeline. They love the empowerment of the millions of lines of code the community has built over the years, allowing them to build entire products overnight. It is no secret, however, that to run and operate Kafka and Zookeeper at scale requires a team of dedicated distributed systems engineers, not working on product features, but managing infrastructure.
Our first step towards building the Intelligent Data API was first to build the most reliable Kafka-API-compatible streaming platform in the world. One that would require no code changes to existing enterprise applications and a platform that was able to squeeze every single ounce of performance out of modern hardware.
What’s more is we wanted to build this in the open under a Free and Source Available License - BSL - taking inspiration from our friends at CockroachDB. Redpanda is a new storage engine with one licensing limitation: we are the only company allowed to offer Redpanda as a SaaS. Other than that, we wanted to empower every single Kafka API user to build upon a new storage engine optimized for the new world of superscalar CPUs, 100Gbps NICs and NVMe access times in the low double digit microseconds.
Part 2: Unification of historical and real time data (Shadow Indexing)

Amazon S3 officially launched in 2006. 15 years later and trillions of objects stored, we now have reliable infinite storage. This cheap, infinitely scalable storage is what people call the Data Lake. Think of it like your uncle Larry’s doomsday basement. You put everything in it, with no structure, hoping that one day you can take advantage of it (Larry, if you are reading this, no shame!). In more formal terms, it is a central repository of data with an Object-based API that is infinitely scalable. For developers it provides a simple way to achieve disaster recovery. Within seconds of uploading a file to S3 you get eleven-nines of durability. That’s 99.999999999% probability that after storing 10’000 objects you might lose one in 10 million years. It is an engineering marvel in my opinion.
Redpanda eliminates the need for disaster recovery by integrating with these infinitely scalable storage systems. Instead of deleting data locally, it will push the old segments onto S3 and fetch them when clients need them. On the surface this sounds like the obvious solution in a cloud native world, but what it does for enterprises is that it unifies the way you access and manage both historical and real-time data without changing a single line of code in your application!
We call this feature Shadow Indexing because it doesn’t keep the historical data on local disks, instead it keeps a location reference of how and where to fetch the data should a Kafka API client request it. What enterprises are the most excited about, however, is the fact that you can spin up a new Redpanda cluster and replay petabytes of data to retrain your machine learning model without affecting your production cluster or changing any code. In a way, this presents a true disaggregation of compute and store for streaming data.
Part 3: Ship code to data

As data accumulates, it builds sort of a gravitational pull, attracting applications to interact with it, in turn generating more data. The more data is collected, the stronger the pull for other applications to interact with it, ad infinitum. If you are a developer working with real-time data streaming applications you understand that as soon as a component touches Kafka or in our case Redpanda, the higher the propensity for applications interacting with it to also integrate with the Kafka-API. In fact, the system was explicitly designed from day-0 to be a way to decouple multiple disparate systems and API’s by simply using the Kafka API. Redpanda, through the Kafka API, is a viral primitive, one that is scalable, secure, fast, durable, replayable and integrates with just about every single other data framework in existence today.
Instead of fighting data gravity, Redpanda inverts the typical paradigm of sending data to compute frameworks like Spark Streaming, etc and instead allows developers to ship code to the storage engine. At the lowest level we use WebAssembly, an intermediary language that allows software engineers to write and edit code in their favorite programming language to perform one-shot transformations, like guaranteeing GDPR compliance by removing personal information or to provide filtering and simple aggregation functions. Think of these transformations as the modern day stored-procedures for streaming data.
Conclusion
One of the reasons we are developing Redpanda in the open is because we believe in the power of community. Today, we are happy to announce that we will be releasing our Wasm engine as part of the BSL license on GitHub. While the Kafka API is ready for production, and we hope you put us through the paces, Shadow Indexing and WASM are still in experimental mode but we invite you to try them!
Please join us on Slack or, if this is the kind of technology you want to hack on, we are hiring - consider joining our team. From all of us at Redpanda, we hope to see you soon!

Let's keep in touch
Subscribe and never miss another blog post, announcement, or community event. We hate spam and will never sell your contact information.


